Zilla Plus on Confluent Cloud: Aklivity Zilla Benchmark Series (Part 2)
Zilla Plus delivers near-zero latency overhead on Confluent Cloud at every operationally relevant percentile, and actively improves tail latency where it matters most.



Introduction
In Part 1 of this benchmark series, we showed that Zilla Plus in front of a self-managed Apache Kafka cluster on AWS EC2 delivers up to 2x lower p99 latency compared to bare Kafka. Part 2 raises a harder question: what happens when you place Zilla Plus in front of Confluent Cloud, a fully managed, already-optimised Kafka service? Can a proxy still add value without adding meaningful overhead?
Our finding: At p99, Zilla Plus adds fewer than 3 ms on publish and 4 ms end-to-end. Beyond p99.9, the proxy actually reduces latency by 6–10%, smoothing out the tail spikes that Confluent Cloud alone exhibits under sustained load.
Why Confluent Cloud? & What Does Zilla Unlock?
Confluent Cloud is the most widely adopted managed Kafka offering.
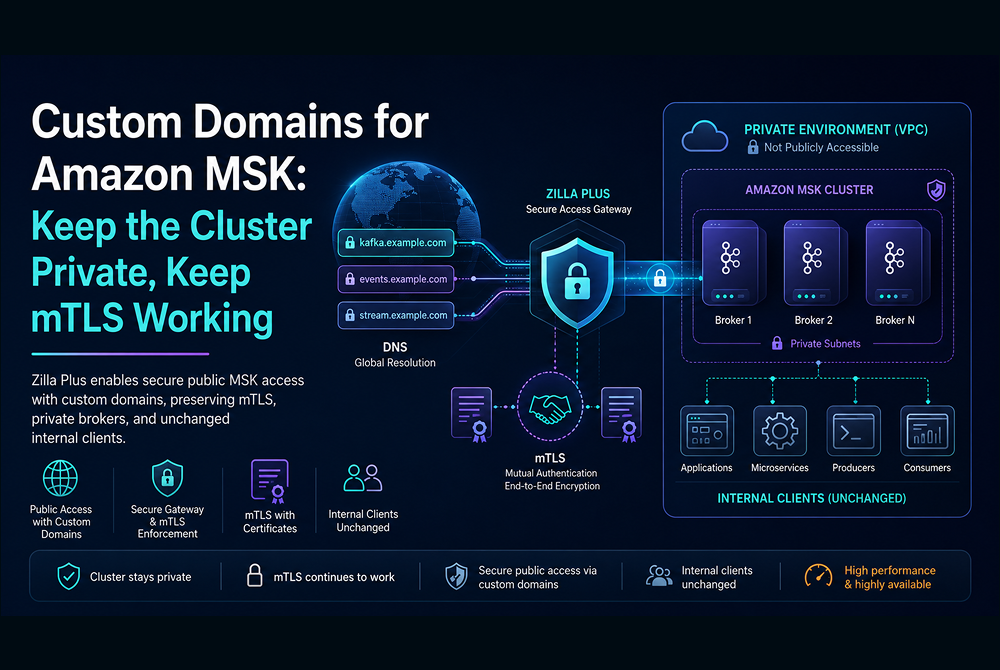
Placing Zilla Plus in front of it unlocks capabilities the managed service alone does not provide:
- Secure Public Access: expose Kafka topics via a hardened, externally reachable endpoint without opening cluster credentials to the internet.
- Multi-Tenant Virtual Clusters: partition a single Confluent Cloud cluster into isolated virtual clusters per team, product, or customer.
- Multi-Protocol Gateway: serve Kafka, MQTT, gRPC, HTTP/SSE, and WebSocket clients from the same broker without protocol adapters or connectors.
- Fine-Grained Access Control: API key management, rate limiting, and topic-level RBAC at the edge, independent of Confluent's IAM.
The question is whether these capabilities come with a latency cost on top of an already-optimised managed service. This benchmark answers that directly.
Benchmark Setup
We use the same OpenMessaging Benchmark (OMB) framework and fork from Part 1, with Confluent Cloud replacing the self-managed Kafka cluster as the backend.
Deployment Configurations
- Confluent Cloud (baseline): benchmark clients connect directly to Confluent Cloud brokers.
- Zilla Plus + Confluent Cloud: benchmark clients connect through Zilla Plus instances on AWS EC2, which proxy traffic to the same Confluent Cloud cluster.
Infrastructure
Workload Configuration
Results
Publish Latency
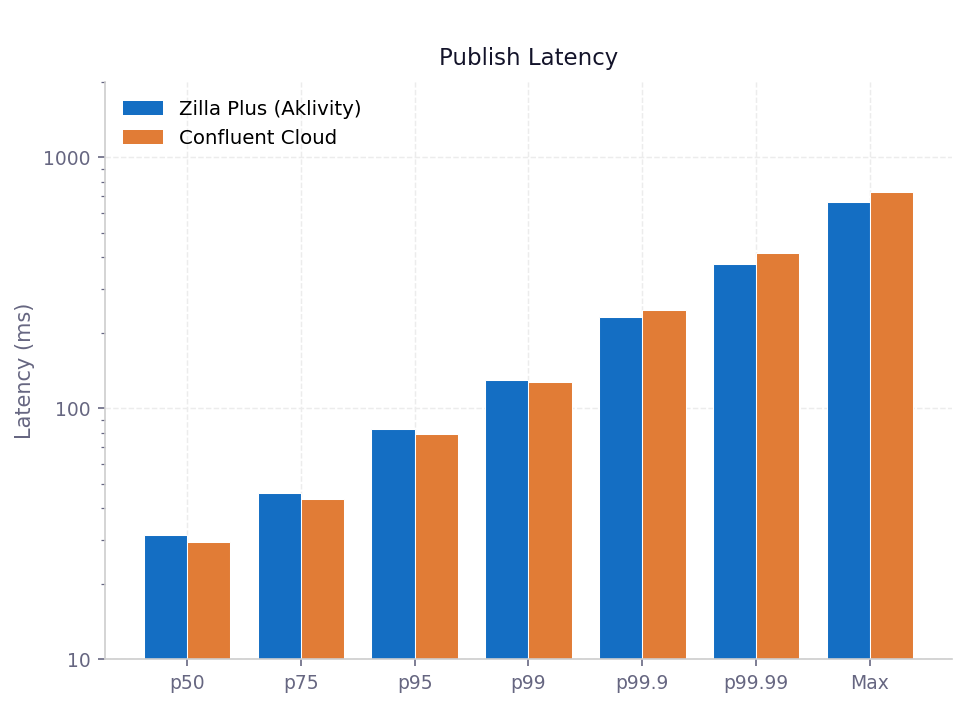
A positive Difference means Zilla adds latency relative to direct Confluent Cloud; a negative value means Zilla is faster.
The overhead at p50 through p99 reflects the additional network hop through Zilla, and stays within 3 - 4 ms in absolute terms. The more significant story is the crossover at p99.9 and above: Zilla Plus absorbs the latency spikes that Confluent Cloud alone exhibits under sustained load, delivering 6 - 10% lower tail latency. Rather than amplifying tail behaviour, Zilla's lock-free, stateless data path actively dampens it.
Publish p99 latency over time
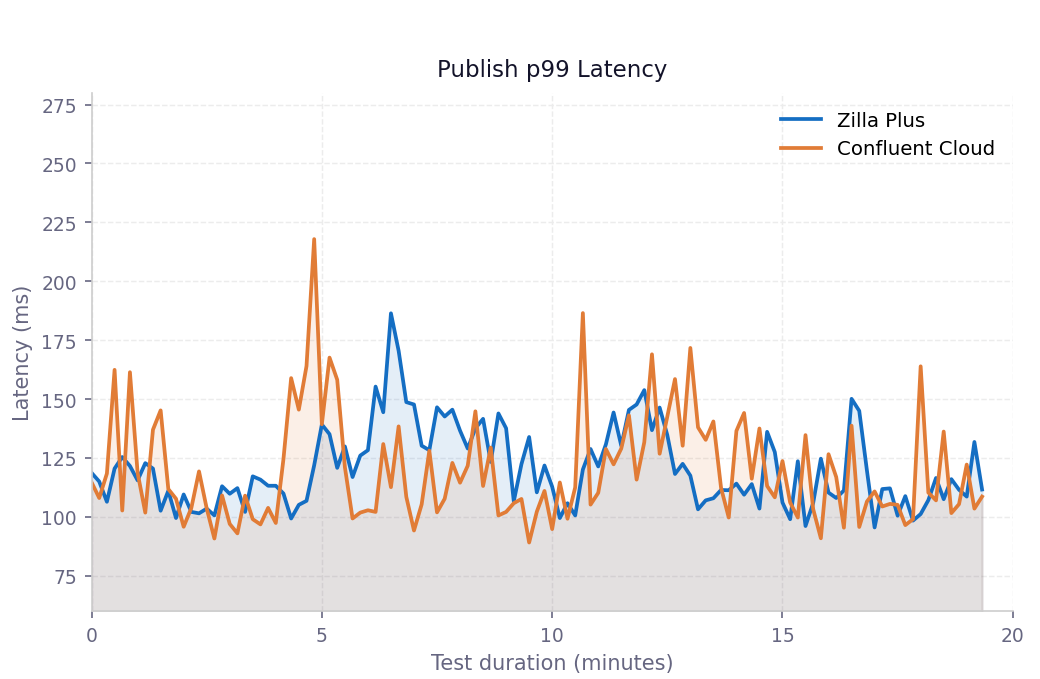
Both configurations track closely throughout the 20-minute window. Zilla Plus shows no progressive drift, confirming the proxy introduces no systematic temporal overhead. The Confluent Cloud line exhibits sharper periodic spikes while Zilla stays in a tighter band.
End-to-End Latency
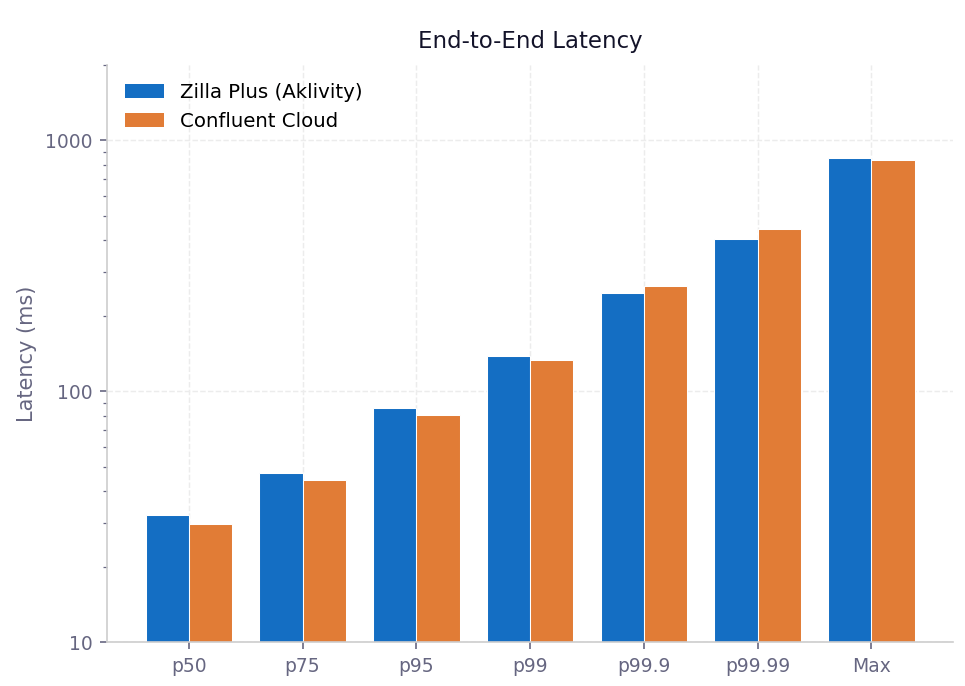
The end-to-end pattern mirrors publish latency: a small overhead at the median and p99, followed by a clear advantage at the tail. At p99.9, Zilla Plus is 15 ms faster end-to-end than direct Confluent Cloud.
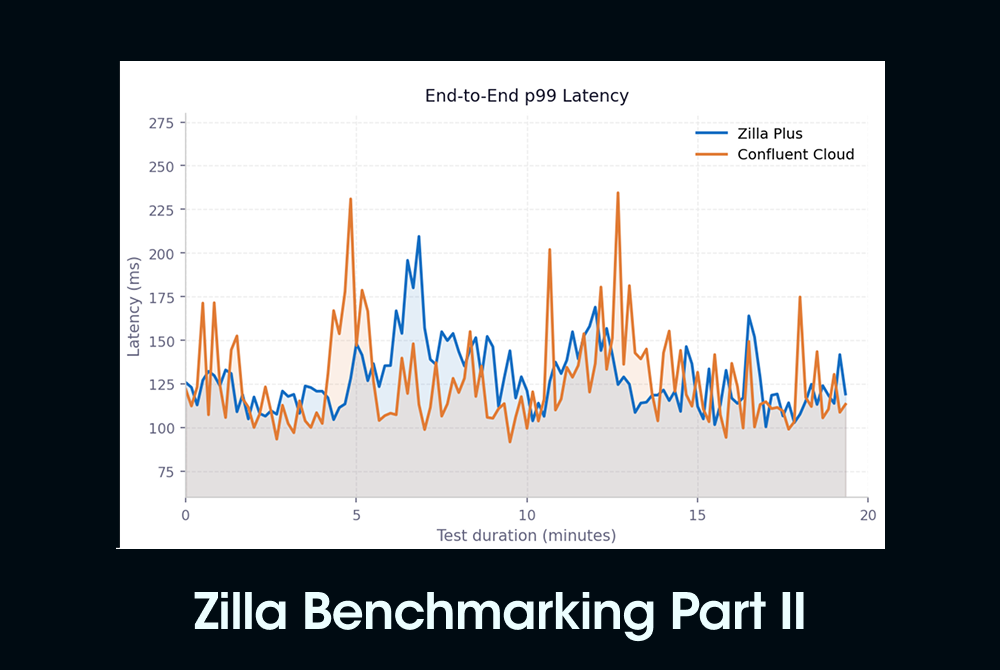
End-to-end p99 latency over time
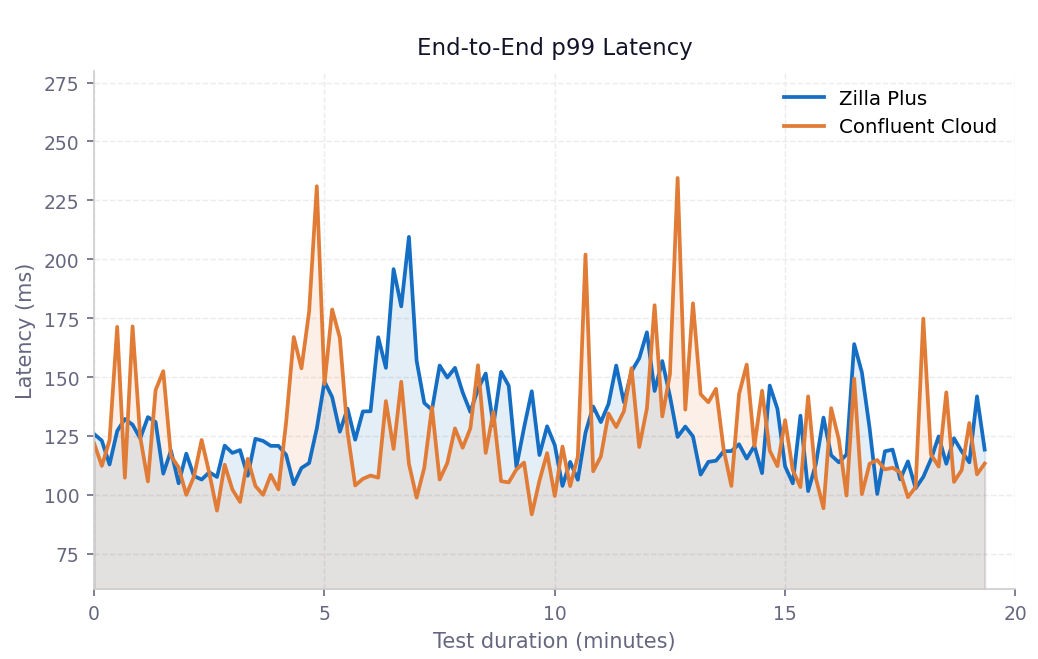
Confluent Cloud alone exhibits sharper, more frequent spikes, some reaching 220 - 230 ms, while Zilla Plus consistently stays closer to the 120 - 150 ms band, reducing tail variance across the test window.
Key Observations
Zilla effective throughput is 2x the workload rate. As a bidirectional proxy, Zilla Plus handles both the inbound client traffic and the outbound broker traffic simultaneously. While the benchmark targets 100 MB/s, each Zilla instance is effectively moving ~200 MB/s of aggregate network traffic. This makes the latency results even more notable: Zilla is processing double the data volume while still matching or beating direct Confluent Cloud latency at the tail.
Zilla CPU utilisation is balanced and well within headroom. Across the three m5.xlarge Zilla Plus instances, CPU load balanced across all four cores at approximately 65%, leaving substantial room before saturation. Zilla's one-worker-per-core architecture ensures this balance by design.
Latency spikes in Confluent Cloud correlate with cluster CPU spikes. The periodic latency spikes visible in the Confluent Cloud time-series align directly with CPU load events in Confluent Cloud's cluster metrics.
Confluent Cloud limitation at the 30/60 scenario. When connecting directly to Confluent Cloud, we consistently observed significant performance degradation after approximately 39 minutes under sustained 100 MB/s load. This instability motivated the 10/20 scenario used throughout this benchmark.
Conclusion
Zilla Plus delivers near-zero latency overhead on Confluent Cloud at every operationally relevant percentile, and actively improves tail latency where it matters most. Teams can deploy Zilla Plus in front of Confluent Cloud to gain secure public access, multi-tenant virtual clusters, and multi-protocol support without sacrificing their latency profile, and in many cases improving it.
Resources


Ready to Get Started?
Get started on your own or request a demo with one of our data management experts.