Confluent Platform + Zilla Platform: Better Together or Better Prepared?
Zilla fills architectural gaps in Confluent deployments without replacement, adding future flexibility.




What This Guide Covers
Confluent is the most feature-rich Kafka vendor on the market. For many organizations, it's the right choice, and it stays the right choice.
This guide isn't about replacing Confluent. It's about understanding the architectural gaps that emerge in production Confluent deployments and how Zilla Platform addresses them without requiring you to rip anything out.
Two questions frame the comparison:
Better Together — Can Zilla Platform solve real problems for teams already running Confluent?
Better Prepared — If your Kafka strategy changes, does adding Zilla now reduce future migration cost?
The answer to both is yes. Here's why.
The Confluent Landscape in 2026
Confluent offers two deployment models: Confluent Cloud (fully managed SaaS on KORA) and Confluent Platform (self-managed on-prem). The product surface is the broadest of any Kafka vendor — Schema Registry, Stream Governance, Flink-based stream processing, 200+ managed connectors, Cluster Linking, Tableflow, and as of Q1 2026, Queues for Kafka (KIP-932) and Confluent Intelligence.
It's a strong platform. But breadth creates complexity, and complexity creates gaps.
Six Production Realities Confluent Customers Face
1. Cost escalation at scale. Confluent Cloud pricing is throughput-based — per GB in/out plus compute, partitions, storage, and data transfer. Cross-AZ replication, connector egress, Flink compute, and governance features each carry separate charges. At production scale, Confluent Cloud is consistently cited as the most expensive Kafka option.
2. Cluster type fragmentation. Basic, Standard, Enterprise, Dedicated, Freight — each with different feature availability and hard limits on partitions, connections, RBAC support, and request rates. Basic clusters don't support RBAC for Kafka resources at all. Throughout 2026, Confluent is enforcing stricter limits across all cluster types. Choosing the wrong tier is a common source of production pain.
3. Governance is gated by tier. Stream Governance — lineage, catalog, data quality rules — is a premium feature. Organizations on Basic or Standard clusters have no RBAC for Kafka resources and limited governance tooling. The 10,000-rule-per-cluster limit on access control can also constrain large multi-tenant deployments.
4. External access requires another component. Dedicated clusters support PrivateLink, but if partners or external apps need Kafka access, Confluent's Gateway component must be deployed and managed separately. Basic and Standard clusters only support public internet endpoints. There's no simple, built-in path for controlled partner access to a private cluster.
5. Vendor lock-in deepens with adoption. Confluent's most valuable features — Cluster Linking, Tableflow, Confluent Intelligence, Flink SQL integration — are proprietary. The more deeply you adopt them, the harder it becomes to migrate. Schema Registry's licensing now restricts competing SaaS offerings.
6. Platform reshuffling continues. The 2024 WarpStream acquisition, ksqlDB deprioritized in favor of Flink, Freight clusters for cost-sensitive workloads — these strategic pivots mean features shift between tiers and deprecation cycles. Planning around a moving target is operationally expensive.
None of these are reasons to leave Confluent. They are reasons to add an operational layer that addresses them.
What Zilla Platform Is (and Isn't)
Zilla Platform is a streaming-native operational management layer that sits in front of any Kafka deployment — Confluent, MSK, Redpanda, Aiven, Apache Kafka, or Cloudera. It consists of:
Data Plane — Zilla Gateway, a high-performance stateless proxy that handles protocol translation, security enforcement, policy execution, and streaming message delivery between clients and Kafka.
Control Plane — A management console that provides governance, configuration, lifecycle management, and a self-service developer portal for Kafka environments and API Data Products.
What Zilla Platform does:
- Kafka Endpoints with policy enforcement (topic rules, producer/consumer runtime rules, schema validation, rate limiting)
- API Data Products — package Kafka topics as discoverable, subscribable data products with plans, security, and rate limits
- Self-service developer catalog with application registration, subscription management, and API key provisioning
- Data privacy controls — field-level encryption, PII classification, policy-enforced redaction
- Secure client onboarding via mTLS certificate management
- Monitoring and observability — protocol-level metrics, client health, Grafana integration, alerting
- Multi-protocol translation — HTTP/SSE, WebSocket, MQTT, gRPC to and from Kafka
What Zilla Platform does not do:
- Stream processing (Flink, ksqlDB)
- Managed connectors (Kafka Connect)
- Tiered storage
- Cluster operations or auto-scaling
- Disaster recovery or multi-region replication
Zilla operates at the access, governance, and operational layer. Confluent operates at the infrastructure and processing layer. They don't overlap — they stack.
Better Together: Zilla Solving Real Confluent Gaps
Gap 1: Governance on Every Tier
The problem: Basic and Standard clusters lack RBAC for Kafka resources. Governance features are gated behind Enterprise and Dedicated tiers. Organizations end up paying for premium tiers just for access control.
Zilla's answer: Zilla Platform's Kafka Endpoints enforce topic-level policies, producer/consumer runtime rules, and schema validation in front of any Confluent cluster — including Basic and Standard. Governance enforcement happens at the proxy layer, not the broker layer. You get Enterprise-tier governance without the Enterprise-tier price.
Gap 2: External and Partner Access Without Confluent Gateway
The problem: Partners and external applications need Kafka access, but Dedicated clusters are behind PrivateLink. Confluent's Gateway component must be deployed and managed as a separate self-managed piece of infrastructure. Basic/Standard clusters only expose public internet endpoints with no fine-grained access control.
Zilla's answer: Zilla Gateway sits in front of any Confluent deployment and provides protocol-native Kafka access with authentication, rate limiting, and schema enforcement at the edge — without Confluent's proprietary Gateway. Partners connect through Zilla with per-partner API keys, rate limits, and topic scoping. The Confluent cluster stays private.
Gap 3: Self-Service Developer Onboarding
The problem: Confluent Cloud's UI provides basic resource management, but there's no built-in self-service catalog for developers to discover data products, subscribe, and get credentials without filing tickets to the platform team.
Zilla's answer: Zilla Platform's API Data Product catalog lets developers browse available data products, register applications, create subscriptions, and receive API keys — all self-service. Admins control visibility scopes (org-wide, domain, external) and can expire or rotate keys. The platform team sets the policies; developers self-serve within them.
Gap 4: Multi-Protocol Access for Non-Kafka Clients
The problem: Trading dashboards, mobile apps, IoT devices, browser-based UIs — they need Kafka data but don't speak the Kafka protocol. Confluent has no native support for HTTP/SSE, WebSocket, MQTT, or gRPC access to Kafka topics. Teams build custom consumer services and API middleware.
Zilla's answer: Zilla Gateway translates HTTP/SSE, WebSocket, MQTT, and gRPC to and from Kafka natively at the edge. No middleware services. Schema enforcement and per-client rate limiting at the gateway. Browser-based apps consume Kafka data over SSE. IoT devices publish over MQTT. The gateway handles it.
Gap 5: Cost-Tier Optimization
The problem: Organizations upgrade to higher Confluent tiers primarily for governance and access control features, not for throughput or storage capacity. Premium tiers are expensive, and the cost delta is driven by feature access rather than infrastructure needs.
Zilla's answer: By handling edge concerns — auth, rate limiting, schema enforcement, observability, and governance — Zilla enables organizations to run on lower Confluent tiers and fill the feature gaps externally. Enterprise instead of Dedicated. Standard instead of Enterprise. The cost savings come from not paying Confluent's premium for capabilities Zilla provides independently.
Better Prepared: Vendor Abstraction as Architecture
Even if you're happy with Confluent today, the Kafka landscape is shifting. WarpStream's acquisition, Confluent's ongoing tier restructuring, ZooKeeper's May 2026 end-of-life, and the broader trend toward multi-vendor and multi-cloud architectures all create reasons to decouple your clients from your broker.
How Zilla Creates Vendor Independence
API Data Products abstract the connection string. When clients connect through Zilla, they connect to a fixed, Zilla-managed Kafka bootstrap server — not to Confluent's broker endpoint. If you later migrate from Confluent Cloud to MSK, Redpanda, or self-managed Kafka, clients don't need reconfiguration. The migration is invisible to consumers.
Governance lives above the vendor. Policies, schemas, rate limits, access controls, and developer subscriptions are defined in Zilla Platform — not in Confluent's tier-gated governance layer. If you switch vendors, your governance model doesn't reset. It carries over.
Protocol translation is vendor-neutral. HTTP/SSE, WebSocket, and MQTT clients connected through Zilla are agnostic to the Kafka backend. Whether Kafka is served by Confluent, MSK, or Apache Kafka on bare metal, the client contract remains the same.
What This Means Practically
Adding Zilla in front of Confluent today gives you three things simultaneously:
- Immediate operational value — governance, self-service, partner access, multi-protocol support
- Cost leverage — run on lower tiers, fill gaps with Zilla
- Migration optionality — if you ever need to move, the hardest part (client reconfiguration) is already solved
You don't need to plan a migration to benefit from migration readiness. Decoupling is an architectural improvement that pays for itself on day one.
Head-to-Head: Where Each Platform Leads
Deployment Architecture
Zilla Platform deploys on Kubernetes via Helm, with cloud-specific charts for AWS, Azure, and GCP. The architecture is straightforward:
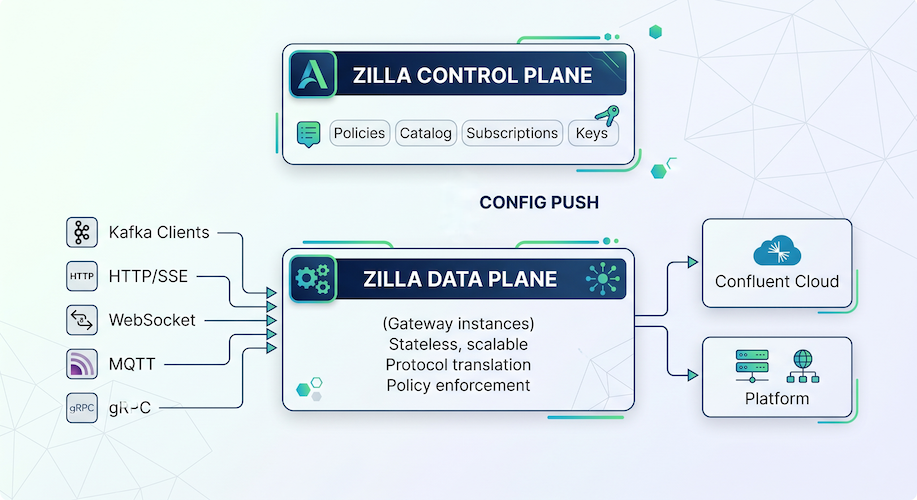
The data plane is stateless and horizontally scalable. The control plane manages configuration and pushes it to gateway instances. Both planes can run independently — the gateway functions even if the control plane is temporarily unavailable.
Who Should Read This Twice
You're on Confluent Basic or Standard and need governance, RBAC, or partner access that's gated behind higher tiers. Zilla fills those gaps without a tier upgrade.
You're on Confluent Dedicated and spending on features you could handle at the edge. Zilla can offset premium tier costs by externalizing auth, rate limiting, and policy enforcement.
You have partners or external consumers who need controlled Kafka access and you're evaluating Confluent's Gateway component. Zilla provides this natively with API key management and per-partner controls.
Your apps aren't Kafka-native. Trading dashboards, mobile apps, IoT devices, browser UIs — they need HTTP, WebSocket, or MQTT. Zilla translates at the edge without middleware.
You're thinking about vendor optionality. Whether you stay on Confluent or eventually diversify, decoupling clients from broker endpoints is an architectural improvement that costs nothing to maintain and pays off if you ever move.
Next Steps
Technical deep-dive. Walk through Zilla Platform's architecture and see a live deployment in front of a Confluent cluster. 20 minutes.
Proof of value. Pick one gap — partner access, governance on a lower tier, or multi-protocol access — and run a scoped pilot.
Full platform evaluation. Map Zilla Platform's capabilities against your current Confluent deployment and identify where it adds immediate value.
→ aklivity.io · docs.aklivity.io/zilla-platform/latest


Ready to Get Started?
Get started on your own or request a demo with one of our data management experts.