Why Every Kafka Team Needs a Vendor-Independent Operational Layer
Your Kafka clients shouldn't know — or care — which vendor is running the brokers.

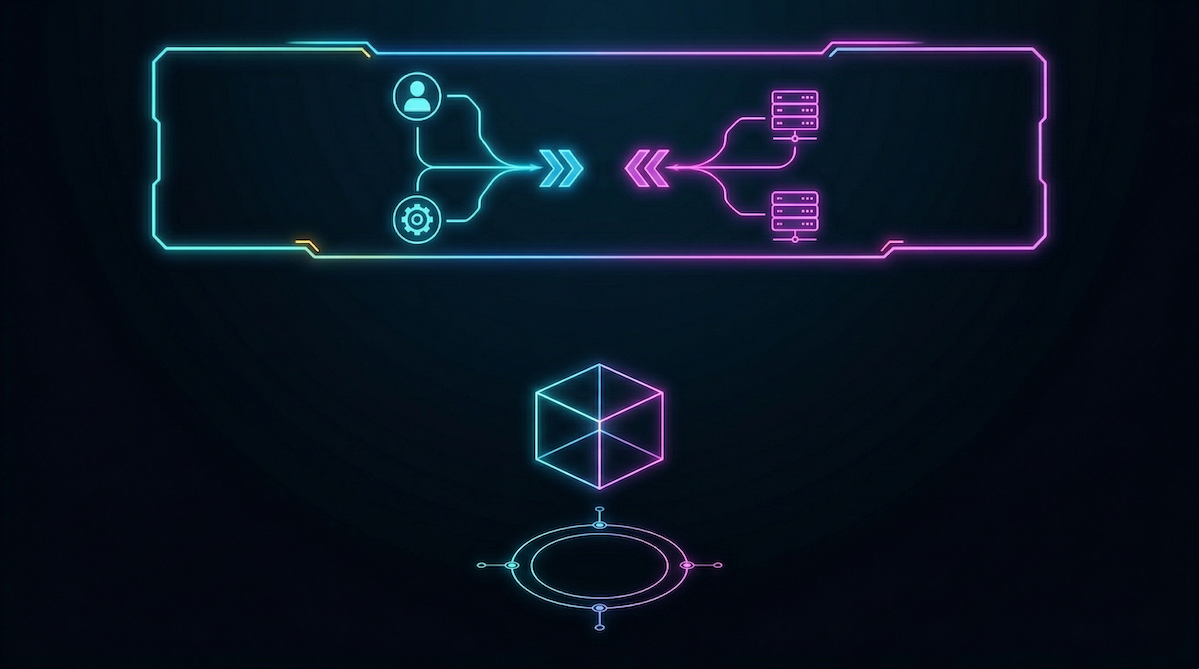


The coupling happens gradually
Nobody decides to create tight vendor dependency on their streaming backbone. It just happens — one practical decision at a time.
You pick a Kafka provider. You connect producers and consumers. It works. Kafka is excellent at its job. Then adoption grows. More teams, more topics, more integrations. And gradually, your entire real-time data infrastructure becomes coupled to a single vendor's tooling.
Schema Registry is vendor-specific. RBAC is vendor-specific. Monitoring dashboards, alerting rules, Connect configurations, client libraries with proprietary extensions — all vendor-specific. Your Kafka clients have hardcoded bootstrap server URLs pointing directly at vendor-managed brokers.
One day someone asks: "What happens if we need to move?"
The honest answer is: a multi-quarter, multi-team project touching every application that produces or consumes from Kafka. That's not a failure of planning. It's the natural consequence of building directly on infrastructure without an operational abstraction layer.
We've solved this everywhere else
No one connects application code directly to a specific database vendor's wire protocol without a driver abstraction. API consumers don't hardcode the IP address of a backend service — they go through a gateway. DNS exists so that infrastructure can change without clients noticing.
While these abstractions are table stakes everywhere else, Kafka deployments routinely skip this step. Clients connect directly to brokers. Governance lives inside the vendor's control plane. The entire operational surface area is coupled to the provider.
This works fine — until it doesn't. And "until it doesn't" can arrive from several directions: a pricing change, a strategic pivot, a need to run across multiple clouds, or simply a better option emerging in the market.
What a vendor-independent operational layer looks like
The concept is straightforward. Place a Kafka-protocol-native proxy between your clients and your brokers. Clients connect to the proxy. The proxy connects to your Kafka provider — whichever one it happens to be.
This enables three things that directly change your operational posture.
Client-broker decoupling
Your applications connect to a stable endpoint that you control. The underlying Kafka provider becomes a configuration detail of the proxy, not a dependency baked into every application. Swapping providers means changing the proxy's backend config — not touching hundreds of client configs across dozens of teams.
Not only does this eliminate migration risk, but it streamlines day-to-day operations. Need to move a workload to a different cluster for cost or compliance reasons? Change the proxy config. Done.
Governance independence
Schema validation, rate limiting, access control, and data quality enforcement happen at the proxy layer — not inside vendor-specific tooling. Your governance model survives a provider change intact. No rebuilding ACLs, no rewriting RBAC policies, no re-integrating monitoring every time something shifts underneath.
This is the one that resonates most with platform teams. Governance is hard to build. Rebuilding it because your vendor changed is demoralizing.
Data productization
This is the capability most teams don't think about until they see it. When you have an operational layer between clients and brokers, you can package Kafka topics as discoverable, subscribable API Data Products — with AsyncAPI specs, usage plans, rate limits, and a self-service catalog.
This is how API management works for REST. There's no reason event streams shouldn't work the same way!
The DIY path
You can build this yourself. The components: a Kafka-protocol-aware reverse proxy, a schema validation layer, an access control and rate limiting engine, a discovery catalog, and observability instrumentation across all of it.
Doable. But it's 6–12 months of dedicated platform engineering — and the result is custom infrastructure your organization maintains indefinitely.
What to look for in purpose-built tooling
Kafka-protocol-native, not just Kafka-adjacent. The proxy must speak the Kafka wire protocol natively so existing clients connect without code changes. An HTTP-to-Kafka bridge is a different pattern — useful, but not transparent Kafka-native proxying.
Stateless data plane. If the proxy requires its own database or persistent storage, you've traded one operational dependency for another. A lightweight, stateless proxy that derives configuration from a control plane is easier to deploy, scale, and recover.
AsyncAPI-driven data products. Auto-derive specs from topics and schemas. Use those specs as the foundation for data product definitions. Machine-readable contracts, not just governance documentation.
Multi-protocol extensibility. Today you need Kafka-to-Kafka proxying. Tomorrow you'll need HTTP/SSE, gRPC, MQTT, or WebSocket access to the same event streams — without deploying separate infrastructure per protocol.
When to adopt this pattern
The short answer: before you need it.
The organizations that adopt a vendor-independent operational layer proactively — while things are stable — get the future-proofing benefit and the immediate operational benefits: self-service access, data productization, governance enforcement, and multi-protocol exposure.
The organizations that wait until a vendor change is forced on them — by pricing, by acquisition, by strategic shift — end up doing the same work under time pressure, with higher risk and less architectural optionality.
Your Kafka deployment is probably your most critical real-time infrastructure. It deserves the same architectural independence you'd give any other foundational system.
The question isn't whether you'll eventually need this layer. It's whether you build it before or after the moment that makes it urgent.
Zilla Platform is an open-core operational layer for Kafka that provides vendor-independent governance, data productization, and multi-protocol access. It connects to any Kafka provider — Confluent, MSK, Redpanda, Aiven, or vanilla Apache Kafka — and decouples your clients from the underlying infrastructure. Learn more or try it with your existing cluster.


Ready to Get Started?
Get started on your own or request a demo with one of our data management experts.