Supercharging Online Sports Betting with Real-Time Data Products
Betting on success with real-time data products powered by Apache Kafka and Aklivity.



Now that “real-time” is no longer just a buzzword or trend, we should focus on building platforms that are natively event-driven, resilient, and designed to meet the expectations of today’s always-connected audience.
But does that always mean tearing down your existing, working flows and rebuilding everything from the ground up? Or is it just a matter of stitching together enough vendor and in-house modules, most of which weren’t built to be event-driven until the system kind of behaves like one? Or something much simpler & event native?
In this blog post, we’ll explore how to supercharge an online sports betting app using Aklivity Zilla, a stateless, declarative, event-driven proxy alongside Apache Kafka to deliver real-time, scalable, and reliable experiences.
Trends & Challenges
As per Mordor Intelligence, the Online Sports Betting Market size is estimated at USD 53.78 billion in 2025, and is expected to reach USD 93.31 billion by 2030, at a CAGR of 11.65% during the forecast period (2025-2030).
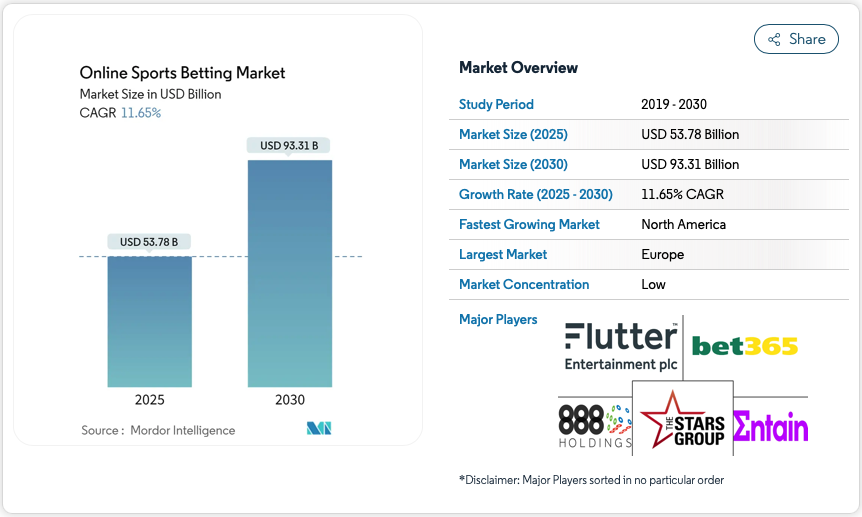
These numbers directly point to the growing popularity and worldwide acceptance of Online Sports Betting platforms. But with this great growth comes great responsibility to meet rising user expectations with fast, responsive, and scalable platforms.
Key Challenges
Legacy Systems
Legacy betting platforms rely on traditional REST APIs and monolithic architectures that weren’t built for real-time streaming or event-driven workloads. Upgrading these systems to Event-Driven architectures presents many challenges like compatibility issues with third-parties modules, integration with Streaming platforms like Kafka, retraining teams who may not be familiar with asynchronous flow and many more.
Scalability
Scalability is one of the biggest challenges for any sports betting platform. Unlike typical applications, betting systems need to cope with huge spikes in user activity when major events are happening. A single championship match or big tournament can bring in hundreds of thousands of people placing bets, checking odds, and cashing out all at once.
Upgrading existing systems to handle auto scaling at both vertical & horizontal presents new challenges & blockers. It’s not just about handling surges either. These platforms often serve users across different countries and time zones, so the system needs to stay fast and reliable for everyone, no matter where they are.
The platform has to handle this massive load without displaying signs of lag & timeouts. Odds updates, bet placements, and transactions need to happen instantly and stay accurate, even with 100,000s of concurrent users. Any delay or inconsistency can hurt the user experience and lead to lost revenue.
Regulatory reforms/Government Regulations
Online sports betting industry faces stringent and evolving government regulations around data privacy & transaction auditing. And for an Application used across the globe, it’s challenging to adapt to region-specific compliance requirements & manage jurisdictional data boundaries.
Omni-Channel Experience
Users expect a seamless and consistent betting experience whether they’re on mobile, desktop, or partner platforms. Managing real-time updates across all these channels without delays or inconsistencies is a complex engineering challenge.
Reconnection & Session Recovery
Mobile users often face network disruptions or switch devices, requiring the platform to gracefully recover missed events without duplication or data loss. Effective session recovery ensures users never miss critical updates.
Idempotency
Ensuring that bet placements and transactions are processed exactly once, even when requests are retried due to failures. It is essential to maintain financial accuracy and user trust. Without idempotency, duplicate bets and errors can easily occur.
Data Governance
Strict regulatory requirements demand comprehensive audit trails, data lineage, and secure handling of sensitive user and transaction data. Platforms must embed governance capabilities to ensure compliance and transparency.
Third-Party Integrations
Securely streaming data to odds providers, analytics systems, and payment processors without exposing internal infrastructure requires careful access control and reliable data pipelines.
Operational Overhead
Combining multiple messaging, API, and streaming technologies often results in complex, brittle systems that require significant maintenance and operational effort. Simplifying this stack is critical for agility and scalability.
AI/ML in Betting: The Next Obvious Step
While we are addressing and figuring out Event-Driven architecture,AI/ML is the next big shift we must prepare our systems for. From personalized user experiences to predictive analytics, fraud detection, and dynamic odds calculation, AI/ML has the potential to elevate the entire betting lifecycle. So the system we build needs to be compatible with protocols like MCP, enabling seamless integration between real-time data streams and AI/ML pipelines.
Real-Time Data Products
What are Real-time data products?
A data product is a self-contained, reusable data asset specifically created, managed, and maintained to deliver consistent, reliable, and actionable insights or services to internal or external users.
What does this mean for the Users?
Real-time data products enable users to rely on the almost real-time data to make informed decisions. This is especially critical in the online sports betting space, where every millisecond can influence the outcome of a bet. Whether it's reacting to live odds, tracking game progress, or confirming bet placement, users expect and depend on up-to-the-millisecond accuracy.
What does this mean for the business?
Data exchange among vendors/partners is a big thing in sports betting. The betting odds often are calculated and originating from a third party source. By delivering live insights and personalized experiences, platforms can drive higher bet volumes, reduce churn, and gain a competitive edge. With AI/ML in the picture this also enables quicker fraud detection, dynamic risk management, and streamlined compliance.
Foundations of Real-time data products
- Event Brokers: Apache Kafka or Amazon MSK or any other flavour of Kafka for durable, scalable, and ordered event streaming.
- Stream Processing: Tools like Apache Flink or Kafka Streams enable complex event processing, aggregations, and stateful computations with low latency.
- API Gateways & Proxies: Event-native proxies (such as Aklivity Zilla) that handle stream subscriptions, protocol translation, idempotency, and reconnection logic at the edge.
- Messaging Protocols: Server-Sent Events (SSE), or MQTT for delivering live updates to client applications.
- API Specification: Industry standard like OpenAPI & AsyncAPI to define, design, and document APIs and event-driven interfaces clearly and consistently.
Shift-Left Architecture
Shift Left in data integration is all about handling data quality and governance right where the data is created. By cleaning and structuring it early, everyone from analytics to AI systems gets fast, consistent access to quality data without the usual downstream mess.
Why Shift Left?
Because prevention is better than cure.
Even though Data Pipelines have improved drastically over the last decade, they’re still no match to the increasingly complex & high-velocity data generated across multiple sources. This leads to Data duplication, inconsistent formats, delayed processing, and fragmented insights making it harder for end users to trust or act on their data in real time.
Shift Left with an Event-Driven Proxy
While traditional flow relies on downstream services/applications to clean, enrich, and route data. An event-driven proxy flips this model by sitting closer to the edge of the system, intercepting, validating, transforming, and routing data the moment it is generated or received. This drastically reduces the compute and I/O overhead on the downstream services & applications, enabling them to focus on core business logic rather than data cleaning, validation, or enrichment. Shift Left approach with Event Driven Proxy like Zilla, enables centralized schema management and data validation across multiple protocols like HTTP, SSE, MQTT, and Kafka.
Built-in Security Controls: Enforces authentication & authorization at the proxy layer, preventing unauthorized or malformed data from propagating into backend systems or consumed by end users.
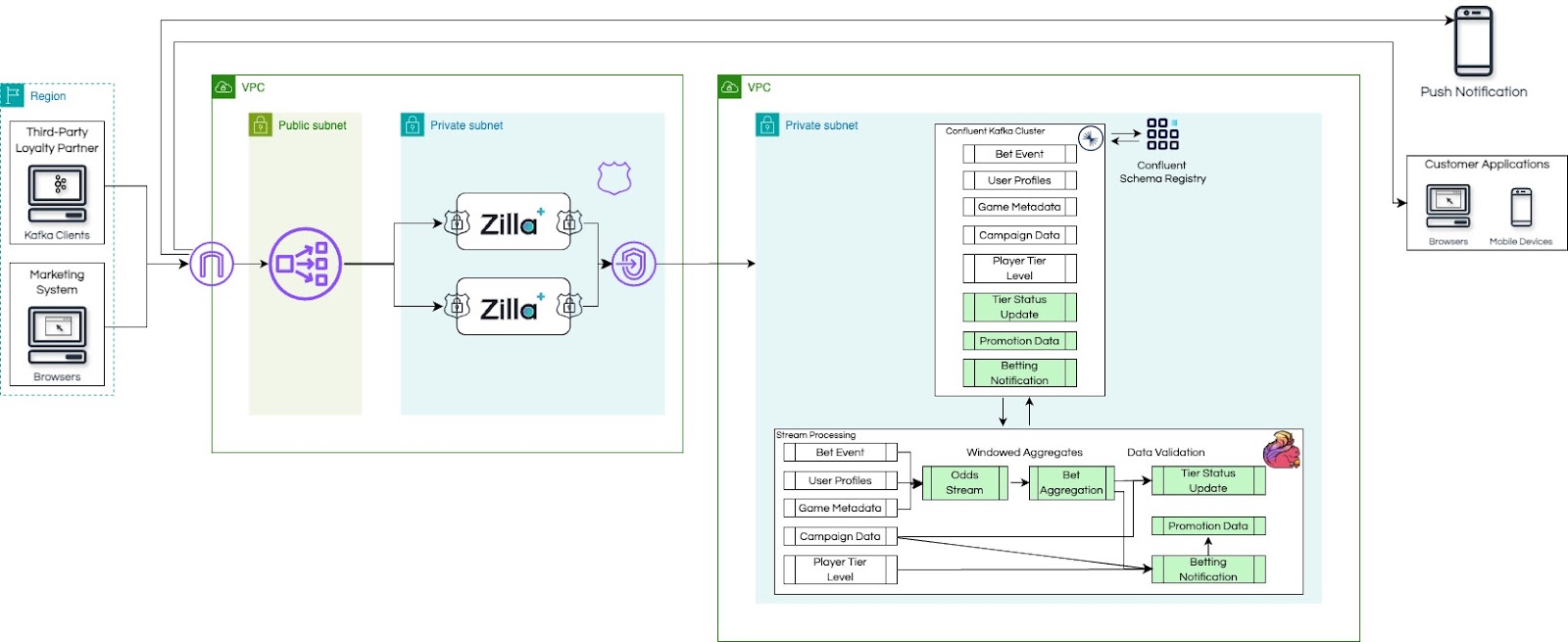
Architecture
This architectural flow, shows an example of Real-time data product with Shift Left approach, highlighting how raw data gets progressively shaped into usable information before hitting core systems.
Amazon MSK
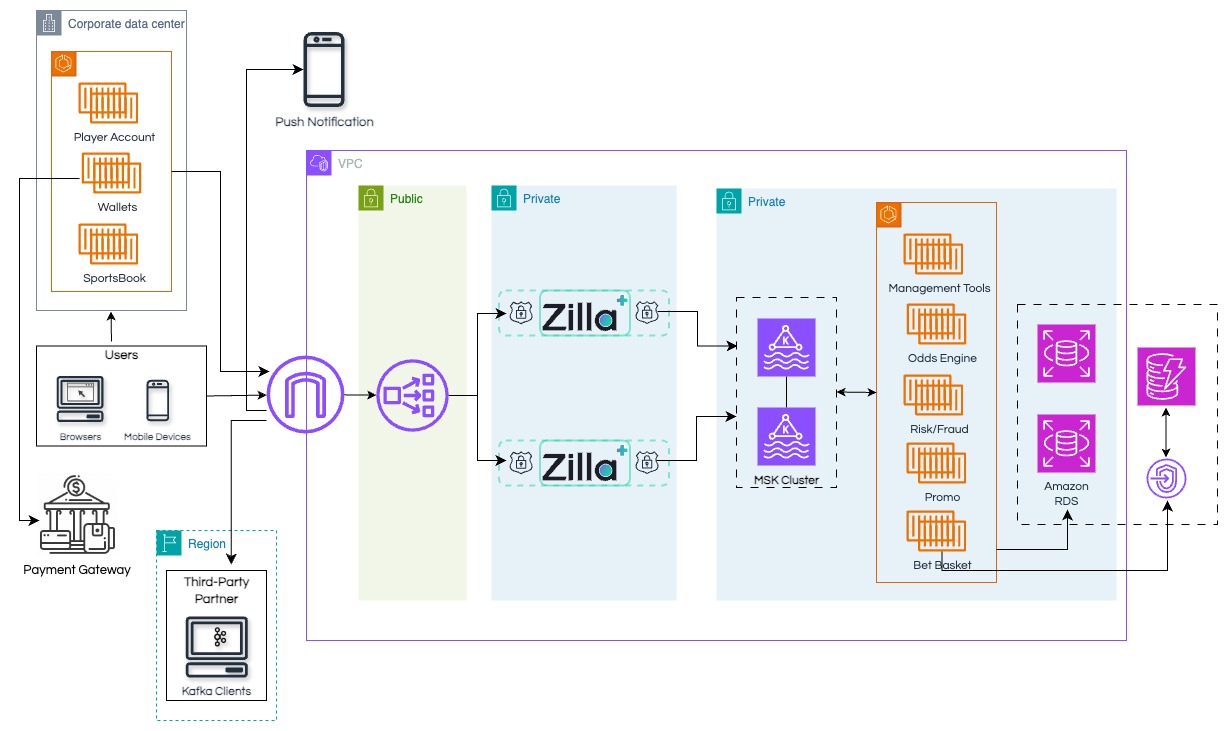
Confluent
Solving the Toughest Challenges in Online Sports Betting
Unstable Connectivity
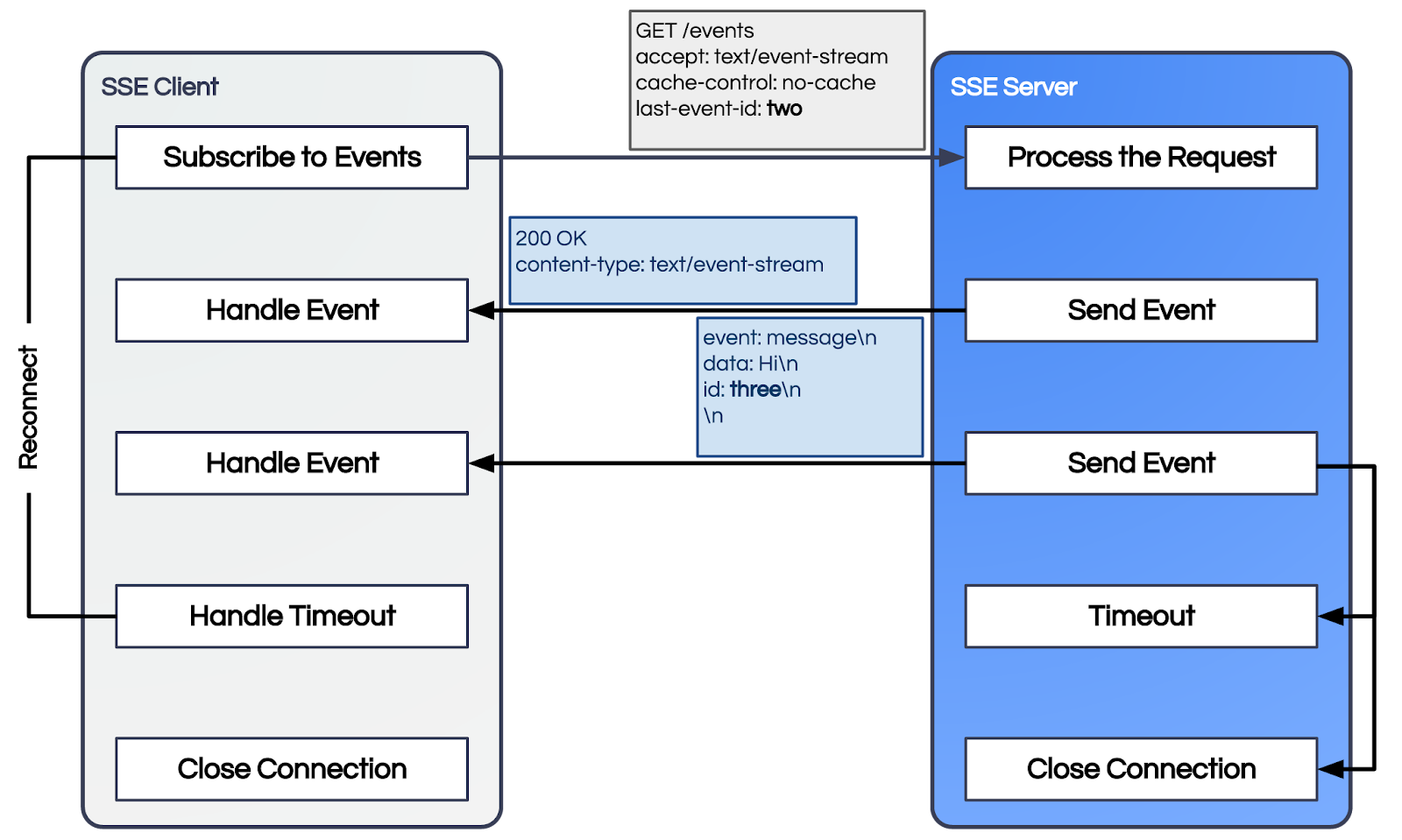
In today’s app-first world, spotty or intermittent network connections remain a fact of life for many users, whether they’re at a crowded stadium, commuting, or simply switching between Wi-Fi and cellular. Though for many applications, this might not be a deal breaker but for high-stakes, time-sensitive platforms like sports betting apps, this can lead to missed opportunities, frustrated users, and financial loss. Zilla’s support for SSE protocol comes with “Auto-reconnect” feature. SSE Binding comes with built-in error handling. When the response between an SSE client and a server is interrupted, the event stream is automatically reestablished. Moreover, if the server sets the id: field in any message already received by the client, then upon reconnecting, the client will send back the last message id: it received inside a Last-Event-ID header.
Duplicate Requests & Retry Storms
Imagine a user placing a bet on a high-stakes game but, due to network lag or a missed acknowledgment, they don’t receive confirmation. Frustrated, they hit the “place bet” button again. From the user’s perspective, they only want to place the bet once but the system ends up receiving multiple requests for the same action. Now, this is a classic example that highlights why idempotency is absolutely essential in online sports betting platforms. To handle retries and duplicates, Zilla supports the idempotency-key header. This ensures that if the same request is replayed intentionally or due to network retries, the Kafka consumer can detect it as a duplicate (based on the idempotency-key and zilla:correlation-id) and safely return the original response or ignore it, preserving the platform’s integrity and user trust.
Inconsistent Data
Betting platforms ingest data from multiple sources like live feeds, odds providers, player stats and many more with different schemas and data types. An event-driven proxy should be capable of validating, transforming, and standardizing this data on the fly.

Partner Integration
Sports betting platforms rely on a complex ecosystem of third-party providers: odds aggregators, payment gateways, identity verification, and so on. Exposing data to these providers can be challenging, especially when partners are not yet event-driven or when platform constraints prevent direct exposure of internal event brokers like Kafka.
Zilla makes it possible to bridge this gap as it can act as Kafka native proxy to exposing topics to partners via AsyncAPIs or OpenAPIs to align with industry standards.
Never-Ending Regulatory Demands
A global Sports betting platform has to be in accordance with local Government regulations, so event-driven solution should meet the global scale of regulatory variation, the platform must support infrastructure-level flexibility as well.
This is where Zilla comes in:
- Deploy Anywhere: Zilla can run in public cloud, private cloud, on-premises, or even at the edge, making it easy to comply with regulatory requirements.
- Stateless by Design: Zilla’s stateless architecture means it can be redeployed, or migrated without the overhead of managing internal state.
Zilla ensures your platform can adapt fast without friction.
Lag in User Experience
In the fast-paced world of sports betting, delays of even milliseconds can cause missed bets or inaccurate odds, leading to lost revenue and unhappy users. To eliminate latency bottlenecks, Zilla brings low-latency, high-performance data delivery right to the edge.
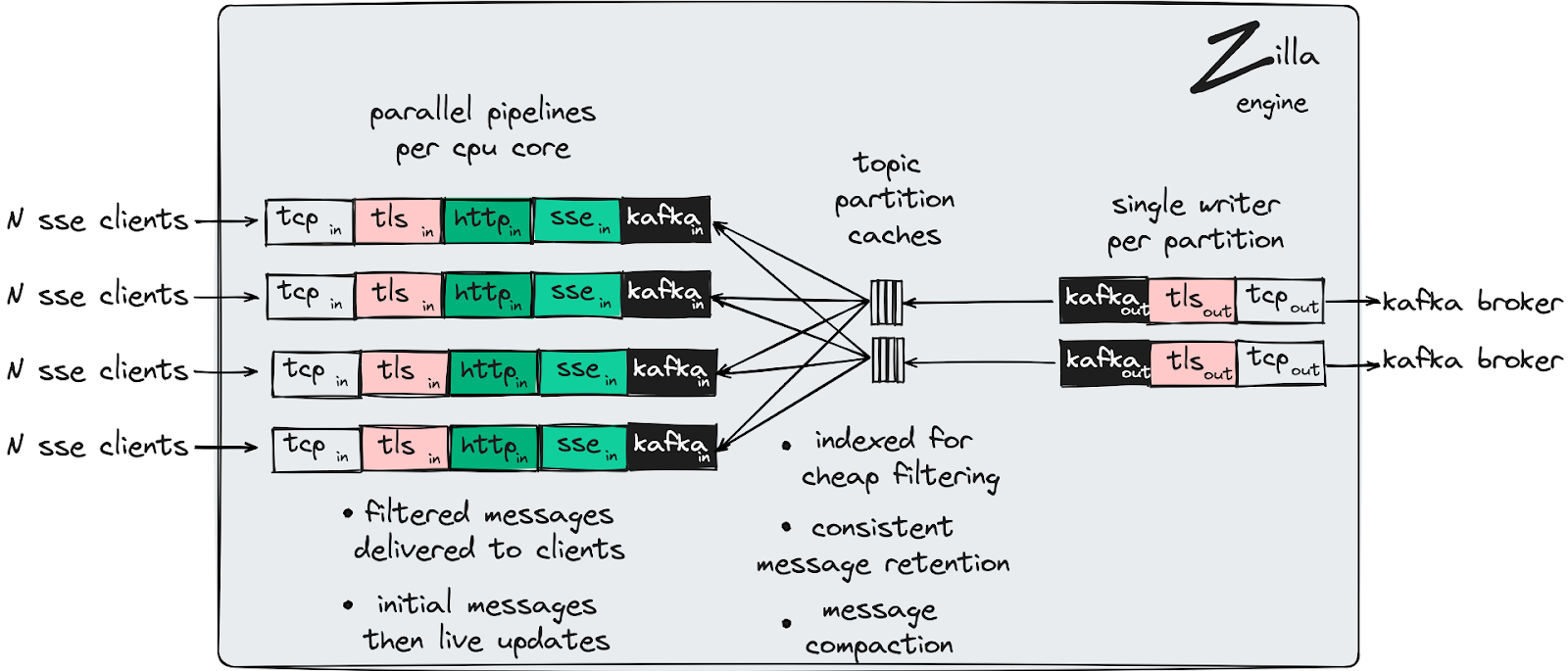
Zilla handles Kafka fan-in and fan-out scenarios efficiently using its Kafka cache binding:
Fan-Out (Fetch): Zilla caches Kafka topic partitions in memory-mapped files, hydrating them from Kafka in near real-time. This allows Zilla to serve messages directly from memory to any number of clients without repeatedly hitting Kafka. Messages are fetched once from Kafka, then distributed to many consumers, drastically reducing network and broker load.
Ready to Handle the Next Big Game
Major sporting events can cause sudden surges in user activity, overwhelming systems unprepared for the spike. Betting platforms must be architected to auto-scale elastically and handle millions of concurrent users without hiccups. Zilla is designed to scale both horizontally and vertically with Auto-Scaling capabilities. Zilla’s telemetry feature exposes metrics data that can be used to trigger Auto Scaling. So when it’s time for the next big game, your DevOps guys can breathe easy.
Staying Vendor Neutral
In today’s ever-changing landscape, having an option to stay decoupled from Streaming platforms gives you the flexibility to explore the best one for the job. Zilla makes this possible by natively supporting protocols natively like HTTP, SSE, Kafka, MQTT, gRPC without relying on external libraries or third-party SDKs. Zilla supports any event broker that understands the Kafka wire protocol, such as MSK, Redpanda, or Confluent Platform, making it easy to interoperate without being tied to a single vendor.

What’s Behind the Scenes?
The star of the show is Zilla — a multi-protocol edge and service proxy built to streamline, secure, and manage event-driven architectures (EDAs) with scalability and performance at its core. Unlike traditional Java-based gateways that rely on frameworks like Netty and suffer from GC pauses and deep call stacks, Zilla avoids object allocation overhead by using code-generated flyweight objects over binary data. Zilla uses this simplified mapping approach to support HTTP, Server-Sent Events, gRPC and MQTT entry points to and from Kafka, such that the client can remain unaware that Kafka is present in the application architecture behind Zilla.
Zilla Architecture
On startup, Zilla parses its declarative configuration and spawns one engine worker per CPU core. Each worker runs independently in a single-threaded context, ensuring no locking or thread contention.
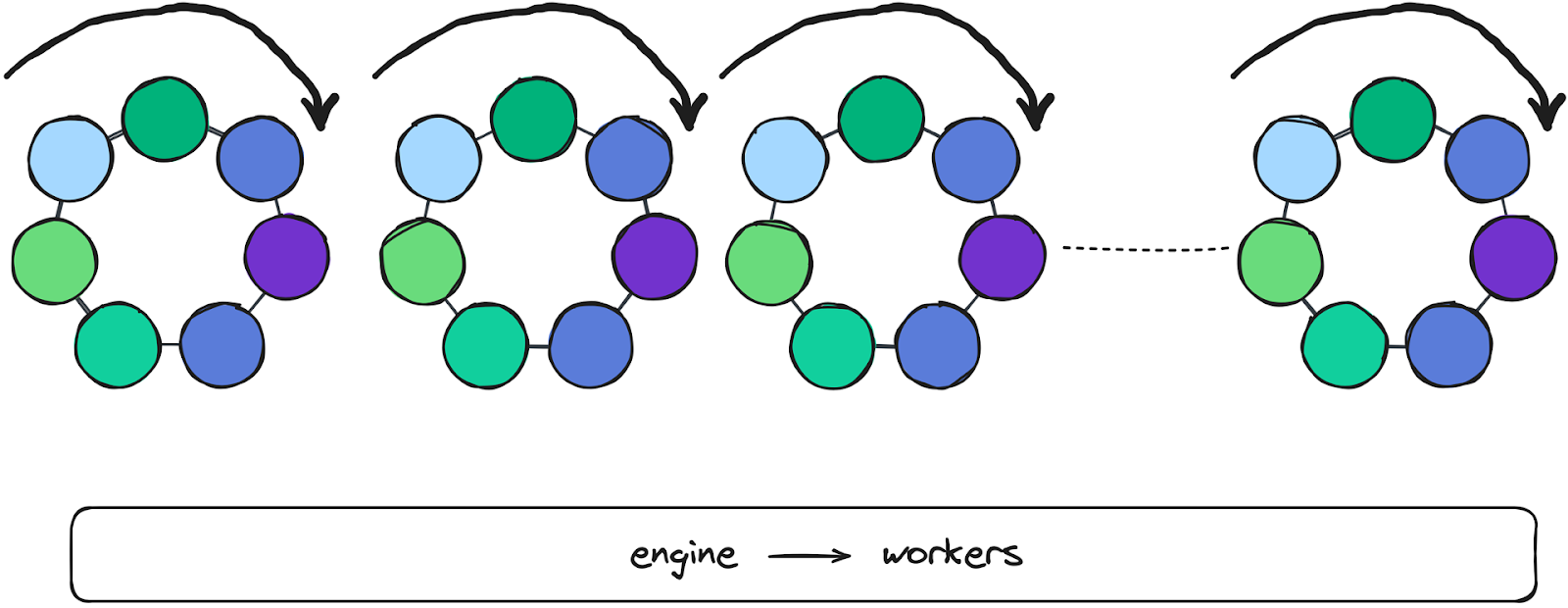
All modular components are instantiated within each worker, enabling consistent behavior across threads. As a result, Zilla naturally scales with the number of CPU cores, maximizing parallelism and throughput.
Demo: Build Faster & Smarter with Zilla
And the best way to conclude this article is with a demonstration of concepts explained above.
We've designed and built a lightweight Sports Betting App based on event-driven architecture that uses HTTP, Kafka, and real-time Server-Sent Events (SSE) to deliver fast, responsive user experiences.
Design
We have used AsyncAPI specification to define both HTTP & Kafka servers, operations, messages & schemas for this demo for a declarative no-code experience.
AsyncAPI: HTTP Spec
Defines RESTful endpoints and SSE channels for real-time client communication, along with structured message payloads.
Preview
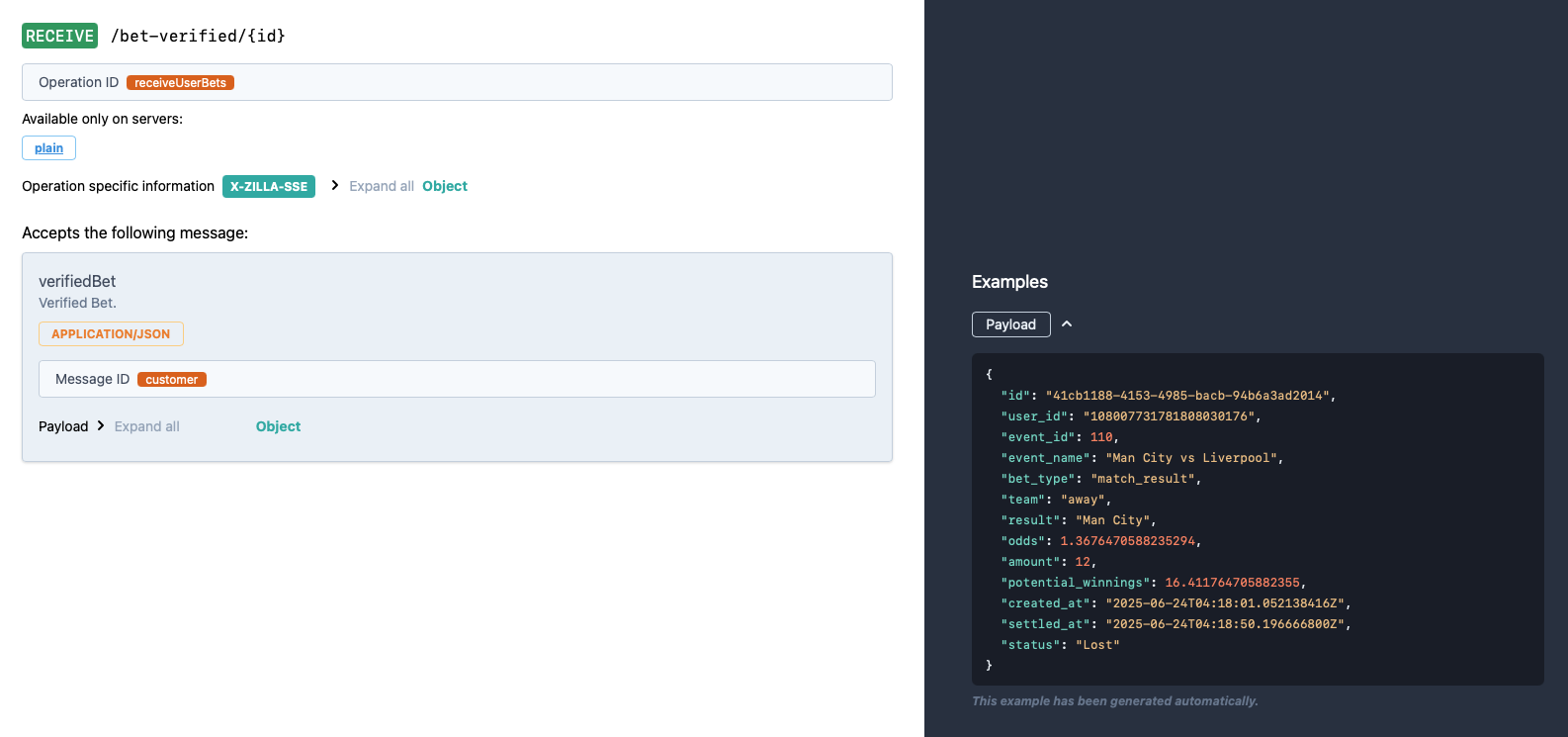
AsyncAPI: Kafka Spec
Specifies Kafka topics for publishing and consuming bet-related events like wagers, odds updates, and match outcomes.
Preview
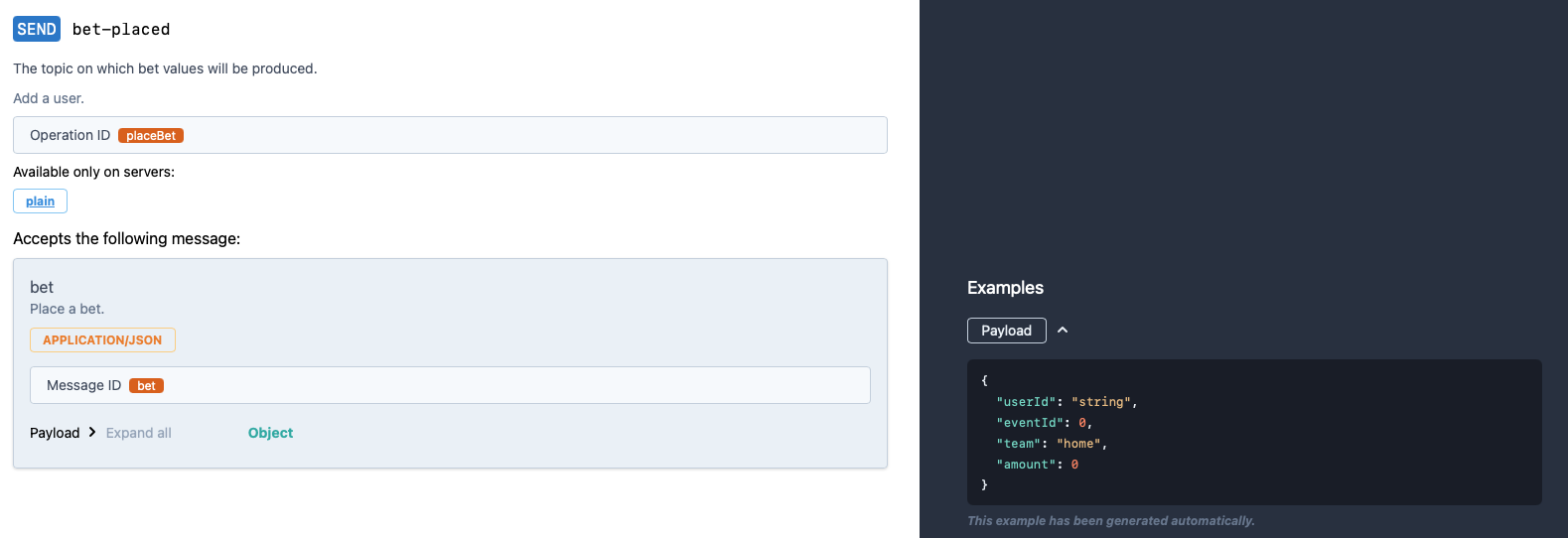
Deploy
Steps to spin up the Sports Betting Demo is quick and effortless as we have used Docker Compose to initialize all the supporting services required as part of this stack.
Refer to this Github Repository for deployment instruction and source code: Zilla Demos: Sports Betting App
Once deployed, the entire stack all works together out of the box. Open your browser and go to: 👉 http://localhost:3000 and start experiencing.
Demo
What’s Next?
We have many such demos and real-world examples published in mentioned Git repositories for you to explore.
Zilla Examples: Hands-on guides and configurations for real world use cases.
Zilla Demos: End-to-end demonstrations of Zilla powering real-time systems.
💬 Join the Zilla Community! Share your experiences and questions on Slack. 🚀



Ready to Get Started?
Get started on your own or request a demo with one of our data management experts.