Rethinking Kafka Migration in the Age of Data Products
Kafka vendor migration has long been treated as an unavoidable disruption. Whether driven by cost, performance, cloud strategy, or vendor risk, migrations typically require months of planning, coordinated client upgrades, and operational risk across dozens or hundreds of teams.




Kafka powers the modern event-driven enterprise. Yet for many organizations, Kafka adoption has quietly introduced a new kind of risk: deep and expensive vendor lock-in.
Recent industry consolidation has forced platform teams and engineering leadership to re-evaluate long-term assumptions around Kafka portability, licensing, and strategic control. Architectural dependency on any single provider carries risk, and future flexibility is no longer guaranteed.
In this environment, the question is no longer whether you trust your Kafka vendor today. It is whether your architecture allows you to change tomorrow. That is the gap Zilla Platform is built to close.
The Gradual Accumulation of Kafka Vendor Lock-In
Over time, platform teams adopt vendor-specific features such as proprietary APIs, schema services, security models, observability tools, and managed service behaviors.
Individually, these choices seem reasonable. Collectively, they create a system tightly coupled to a single Kafka provider. Lock-in does not happen overnight. It accumulates quietly, one dependency at a time, until migration becomes risky, expensive, and disruptive.
How Zilla Platform Solves This
Imagine a platform team running Confluent Cloud that suddenly faces a significant price increase. Migrating looks straightforward on paper, but the reality is a months-long project: applications must be re-pointed to new endpoints, IAM configurations rebuilt, schemas migrated to a new registry, and operational runbooks rewritten from scratch. The cost of switching is not the new vendor. It is everything that was quietly built around the old one.
A vendor-agnostic abstraction layer solves this by decoupling applications from Kafka brokers, separating application access and governance from Kafka infrastructure so that backend changes become a configuration exercise rather than an application rewrite.
Zilla Platform implements this through three planes: a management plane where teams author AsyncAPI specifications, register schemas, and configure access rules; a control plane that continuously reconciles those definitions into runtime configuration; and a data plane that routes and enforces data product access in real time, abstracting the underlying Kafka cluster from producers and consumers.
Data Products: Decoupling Apps From Brokers
Zilla Platform introduces Kafka-native data products that formalize how event streams are exposed and consumed.
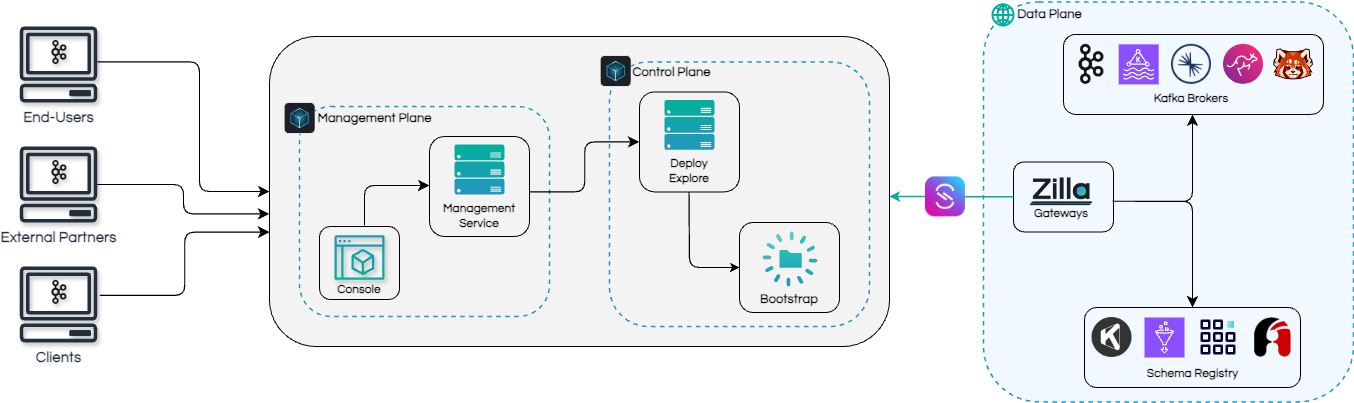
Instead of giving applications direct access to Kafka clusters, platform teams publish governed data products with stable interfaces. Each data product defines:
- What data is exposed
- How it is accessed
- Which clusters back it
- How security and quotas are enforced
Applications consume data products, not brokers.
As organizations grow, unmanaged topic sprawl leads to inconsistent security, unpredictable performance, and fragile governance. Zilla data products let platform teams enforce standards centrally while developers focus on business logic. A single data product can span multiple clusters across vendors, regions, or environments, with governance following the data product rather than the cluster.
From a developer's perspective, consuming Kafka data through Zilla Platform looks the same regardless of where the data lives. Connection endpoints, security configuration, and access policies are standardized behind a self-serve interface, so teams interact with stable, versioned contracts instead of infrastructure-specific details.
Zero-Downtime Migration Checklist
Here is how teams typically adopt Zilla Platform to eliminate Kafka vendor lock-in and migrate without disrupting producers or consumers.
- Get Started with Zilla Platform
- Explore Operational Data Streams
- Extract AsyncAPI Specifications
- Design Real-Time Data Products
- Deploy Real-Time Data Products
- Attach Multiple Kafka Clusters to Zilla Platform
- Re-deploy Data Products against another Kafka Service
- Migrate Client Traffic Gradually in Self-Serve Portal
Business Impact: Cost, Agility, and Long-Term Control
Breaking Kafka vendor lock-in is not just a technical improvement. It has direct business impact.
- Lower migration and switching costs
- Stronger negotiating position with vendors
- Faster adoption of new Kafka offerings
- Reduced operational complexity
- Longer architectural lifespan
Zilla Platform transforms Kafka from a vendor-dependent infrastructure choice into a portable, strategic capability.
Demo: A Real Kafka Migration Journey
Want to see how Kafka vendor lock-in can be broken in practice?
These hands-on demos walk through real migrations between Kafka providers using a phased, zero-downtime approach, whether you are moving from Apache Kafka, Confluent, or another vendor.
You'll see how data is replicated, how access is abstracted, and how client traffic is migrated without changing application code, security settings, or schemas.
Explore the demos: Kafka Migration Demos
Featured Migration Demos
Demo Overview
- Multiple Kafka clusters are attached to a Zilla platform environment
- MirrorMaker replicates data between source and target Kafka clusters
- Existing topics and schemas are extracted into AsyncAPI contracts
- A single governed data product is defined and versioned
- The same data product is deployed against multiple Kafka backends
- Client connectivity, security, and schemas remain unchanged throughout
- Traffic is gradually shifted between backends without redeploying applications
The result is a Kafka migration that happens through configuration and deployment, not application rewrites.
Conclusion
Kafka vendor lock-in is no longer a hypothetical risk. Industry consolidation has made it a practical concern for every organization running Kafka at scale.
Zilla Platform introduces the missing abstraction layer that decouples applications from Kafka infrastructure through governed, Kafka-native data products.
Kafka remains open. Vendors remain replaceable.
Architectural control returns to the platform team.



Ready to Get Started?
Get started on your own or request a demo with one of our data management experts.