Announcing Zilla 0.9.43, featuring support for gRPC, Kubernetes, and more!
New Kafka proxying and cloud-native deployment capabilities are here.




What’s new in Zilla?
The biggest Zilla release since launch is here! With it, we’re thrilled to introduce features that enable a new class of applications and services to take advantage of Apache Kafka. We’ve also made enhancements to further increase confidence when deploying Zilla in production.
In the latest release, Zilla’s Kafka proxying capabilities have been expanded beyond REST and SSE to gRPC, empowering gRPC clients and servers to seamlessly consume and produce event-streams via request-response over a pair of Kafka topics. Integrations with Kubernetes for deployment and Prometheus for monitoring have also been added.
Lastly, to make Zilla’s no-code, fully declarative configuration even more approachable, we transitioned it from JSON to YAML and launched a dedicated VS Code extension that helps create, maintain, and even visualize Zilla configurations!
End-to-end Streaming Between gRPC Services via Kafka
gRPC is an open-source RPC (Remote Procedure Call) framework that many modern microservice architectures have embraced. Its appeal stems from Protobuf, which gRPC uses as a data serialization format enabling strong service contracts and extensive, multi-language code generation. gRPC also relies on HTTP/2 as a transport protocol allowing its services to communicate synchronously and asynchronously, unlike their RESTful counterparts that only support request-response.
While gRPC addresses many of the shortcomings of REST, its services are still temporarily coupled, and their communication is transient. This challenges situations requiring a high degree of service decoupling and resilience. An event-streaming approach based on Apache Kafka, has proven effective in addressing these requirements, and as a result, both gRPC and Kafka-based architectures are often found inside enterprises.
Previously, to reliably bridge the worlds of gRPC and Kafka you’d have to write, deploy and manage your own gRPC Kafka connector, just as the team at WeWork did. But now there’s a much better way!
Introducing gRPC⇔Kafka Proxying with Zilla
Zilla is a Kafka-native, multi-protocol API gateway. With Zilla, apps and services can use standard protocols, such as REST, SSE, and now gRPC, to consume and produce Kafka event-streams.
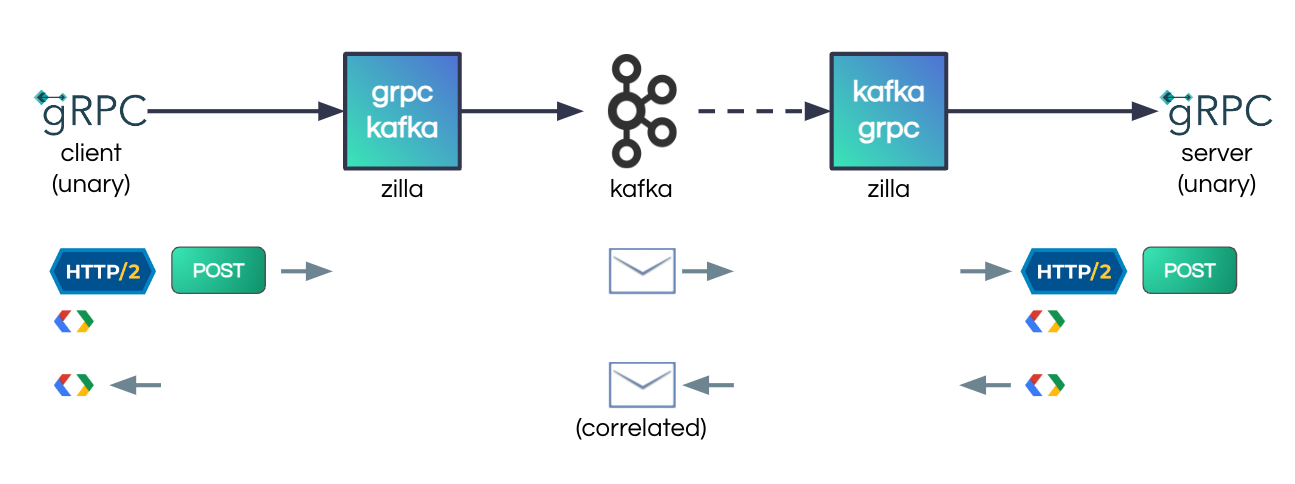
To deliver gRPC-Kafka proxying and enable gRPC clients and servers to communicate over Kafka, we first had to introduce support for the gRPC HTTP/2 wire protocol in Zilla. We then mapped gRPC requests and responses to Kafka streams by routing gRPC service and method names to a pair of request and response Kafka topics, and used gRPC idempotency-keys to generate Zilla correlation-ids (these correlation-ids are injected into Kafka headers to correlate the communication across the Kafka request-response topics). Since gRPC doesn’t have a concept equivalent to a 202 Accepted, we’ve also had to solve for blocked waiting on correlated responses to handle synchronous gRPC interaction patterns.
After tackling request-response we proceed to streaming and mapped gRPC client and server streams to and from Kafka topics. gRPC streaming doesn’t come with guaranteed delivery, but Server-Sent Events (SSE), another protocol that Zilla supports, does. So, leveraging a similar approach to the one found in Zilla’s SSE-Kafka proxy, we added support for a message-id field and last-message-id metadata. As a result, when acting as gRPC streaming server, Zilla supports recovering from an interrupted stream without message loss and without needing explicit receipt acknowledgment from a gRPC client.
Inter-World Opportunities
Zilla makes Kafka look like a gRPC client or server, allowing Kafka event-streams to be consumed and produced via all forms of gRPC communication, i.e., unary, client streaming, server streaming, and bidirectional streaming. This opens up exciting opportunities, including:
- Powerful Analytics — You can observe gRPC request-response streams in Kafka and have an overarching view of your application data across your entire architecture.
- Unified architecture — You can directly reach gRPC services from Kafka services without making any changes to either.
- Flexible architecture — You can migrate gRPC services to Kafka services and take advantage of scaling out via consumer groups, all while retaining original gRPC service contracts.
K8s and More!
Fun fact: after Linux, Kubernetes is the fastest-growing project in the history of open-source software. As a result, adding support for Kubernetes was one of our top priorities.
To make Zilla K8s-ready, we converted Zilla’s JSON-based configuration to YAML and added telemetry capabilities that support auto-scaling. We also created a generic Zilla Helm Chart that bootstraps a Zilla deployment on a Kubernetes cluster for faster testing and easier redeployment inside production environments.
Another fun fact: JSON is a subset of YAML, so feel free to continue matching curly brackets inside a Zilla config file, as anything that parses YAML can also handle JSON!
Exporting Metrics to Prometheus for Auto-Scaling and Observability
Zilla’s Runtime configuration now has two new concepts: metrics and exporters. For metrics, there are higher-level ones that cover gRPC and HTTP requests, as well as lower-level ones for Zilla’s internal data streams. These metrics can be exported to an external monitoring system, specifically Prometheus, for observability and for driving Horizontal Pod Autoscaling on Kubernetes.
Introducing the Zilla VSCode Extension

Zilla’s declarative configuration defines a routed graph of protocol decoders, transformers, encoders, and caches that combine to provide secure and stateless API entry points into Kafka. To help assemble, manage, and even visualize this “graph” inside VS Code, we’ve launched a dedicated extension!
The extension comes with IntelliSense that validates and auto-completes a Zilla configuration YAML, and a visualizer that generates an interactive flow diagram of configured Zilla components.
The Zilla diagram not only helps navigate a Zilla YAML but also validates it, as the location of any missing connections or errors inside a configuration is visually displayed and called out.
But wait, there’s more!
The latest Zilla release also contains a few bug fixes and other improvements, such as support for dynamic HTTP configuration allowing Zilla to be automatically reconfigured when changes are detected in a zilla.yaml file. Please take a look at the release notes for everything new in 0.9.43.
Connect with Us!
The latest and greatest Zilla is now available, complete with documentation and examples, so go give it a try! If you have any questions or feedback, we’d love to hear them. Connect with us on Slack or Twitter, and please help grow the community by starring Zilla on GitHub!


Ready to Get Started?
Get started on your own or request a demo with one of our data management experts.